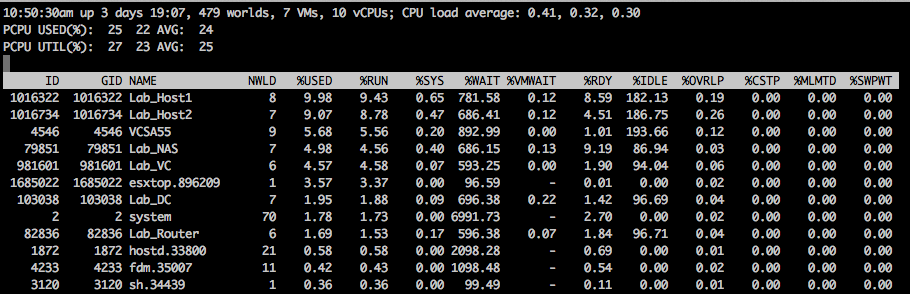
Esxtop é uma ótima ferramenta para análise e troubleshoot de ambientes Vmware, com ela é possível analisar
a utilização de vários recursos do Host de forma simples e clara.
O ideal é usar como consulta para ter uma base, por exemplo se o parâmetro %RDY ficar boa parte do tempo
acima de 20, muito provavelmente a VM irá responder de forma lenta.
Para acessa lo, basta abrir uma sessão ssh no host desejado e digitar: esxtop
Na tela inicial, pressione a tecla f e você verá as opções disponíveis.
Metricas e alertas
| Display |
Métrica |
Alerta |
Descrição |
| CPU |
%RDY |
10 |
Esse costuma ser um item chave, se estiver acima de 10 significa
que a máquina virtual provavelmente tem mais vCPU
(Processador Virtual) configuradas do que realmente precisa. |
| CPU |
%CSTP |
3 |
Alto uso do vSMP, reduza a quantidade de vCPU para essa VM,
dessa forma sobrará mais tempo para agendar as tarefas pendentes. |
| CPU |
%USED |
|
Mostra por quanto tempo a maquina virtual esta gastando
ciclos de CPU do host. |
| CPU |
%SYS |
20 |
Porcentagem de tempo gasto pelos serviços do sistema,
provavelmente devido o alto uso de IO da VM. |
| CPU |
%MLMTD |
0 |
Porcentagem de tempo em que a vCPU estava pronta para
execução porém não foi agendado devido a violação do
limite de CPU, se for maior do que 0 o world (sistema) esta
sendo reduzido devido o limite de CPU. |
| CPU |
%SWPWT |
5 |
A VM esta aguardando as paginas que foram feito Swap serem
lidas no disco, provavelmente a VM esta configurada com muito
mais memória do que precisa. |
| MEM |
MCTLSZ |
1 |
Se for maior do que 0, o host está forçando a VM a executar
a técnica de Balloon para recuperar memória, pois o host
está com mais memória configurada do que a disponível. |
| MEM |
SWCUR |
1 |
Se for maior que 0, o host fez Swap da memória no passado.
A provavel causa é que a VM possui mais memória configurada
do que o necessário. |
| MEM |
SWR/s |
1 |
Se for maior do que 0, o host esta ativamente fazendo leitura
do Swap, a causa provavel é de que existe um alto uso de
memória física. |
| MEM |
SWW/s |
1 |
Se for maior do que 0, o host esta ativamente fazendo a gravação do
Swap, a causa provável é de que existe um alto uso de memória física. |
| MEM |
CACHEUSD |
0 |
Se for maior do que 0, o host esta comprimindo memória,
provavelmente o host está com alto uso de memória. |
| MEM |
ZIP/s |
0 |
Se for maior do que 0, o host está fazendo a compressão da memória
ativamente, a provável causa é de que o host está com alto uso de
memória. |
| MEM |
UNZIP/s |
0 |
Se for maior do que 0, o host está acessando a memória comprimida,
provavelmente a VM estava em um host com alto uso de memória. |
| MEM |
N%L |
80 |
Se tiver abaixo de 80, a VM apresenta problemas com o NUMA, se a
quantidade de memória RAM configurada na VM for maior do que a
quantidade local de cada processador, o agendador não consegue fazer
as otimizações do NUMA para a VM e acaba precisando acessar
memória “remota” via interconexão, para mais pesquise sobre
“GST_ND(X)” para entender melhor sobre como o acesso ao NUMA é
feito. |
| NETWORK |
%DRPTX |
1 |
Os pacotes transmitidos estão sendo perdidos. Hardware
sobrecarregado. Provavel causa, alto uso da placa de rede. |
| NETWORK |
%DRPRX |
1 |
Os pacotes recebidos estão sendo perdidos. Hardware sobrecarregado.
Provavel causa, alto uso da placa de rede, |
| DISK |
GAVG |
25 |
É a soma de “DAVG” e “KAVG”. |
| DISK |
DAVG |
25 |
Tempo médio de resposta da controladora dos discos. |
| DISK |
KAVG |
2 |
Latencia dos discos, causada pelo VMKernel, se o KAVG estiver alto,
provavelmente os commandos estão enfileirando, verifique o “QUED”. |
| DISK |
QUED |
1 |
A fila esta cheia, provavelmente a quantidade de commandos esta
configurada muito baixa, verifique com o fabricante da controladora a
quantidade ideal de comandos “Queue“. |
| DISK |
ABRTS/s |
1 |
Geralmente quando o storage não esta respondendo, a VM envia
commandos abortando a comunicação, Se a VM for Windows isso ocorre
por padrão após 60 segundos. Isso pode ocorrer se um dos caminhos
(path) falhar ou a controladora não estiver aceitando mais commandos
por qualquer razão. |
| DISK |
RESETS/s |
1 |
A quantidade de commandos “reset” por segundo. Cenarios onde
existem múltiplos caminhos, o reset é enviado quando ocorre alguma
falha na comunicação em um caminho com problema. |
| DISK |
RESV/s |
|
São as reservas do SCSI, esse valor só é importante se tiver problemas
com o “CONS/s” |
| DISK |
CONS/s |
20 |
Diz respeito aos conflitos e reservas SCSI por segundo, se muitas
Reservas e Conflitos ocorrerem, impacta o acesso ao VMFS. |
Dicas
Por padrão a tela é atualizada a cada 5 segundos, se quiser diminuir esse tempo, simplesmente digite:
s 3
Assim a atualização acorrerá a cada 3 segundos.
Para alterar as vizualizações basta digitar:
c = cpu
m = memoria
n = rede
i = interrupções
d = adaptadores de disco
u = dispositivos de disco
v = discos das VMs
p = Estado de energia
V = mostra somente as maquinas virtuais
l = limita a mostrar somente um grupo, bom para focar em somente uma VM
Para salvar as alterações digite:
W
esxtop -l